Propensity Score Matching Table

Propensity Score Matching Assessment Download Table

Propensity Score Matching Characteristics Download Table

Propensity Score Matching Download Table

Propensity Score Matching And Covariate Balance Download Table

Propensity Score Matching Showing Standardized Differences 0 1 Download Table

Characteristics Of Patients Before After Propensity Score Matching By Download Table
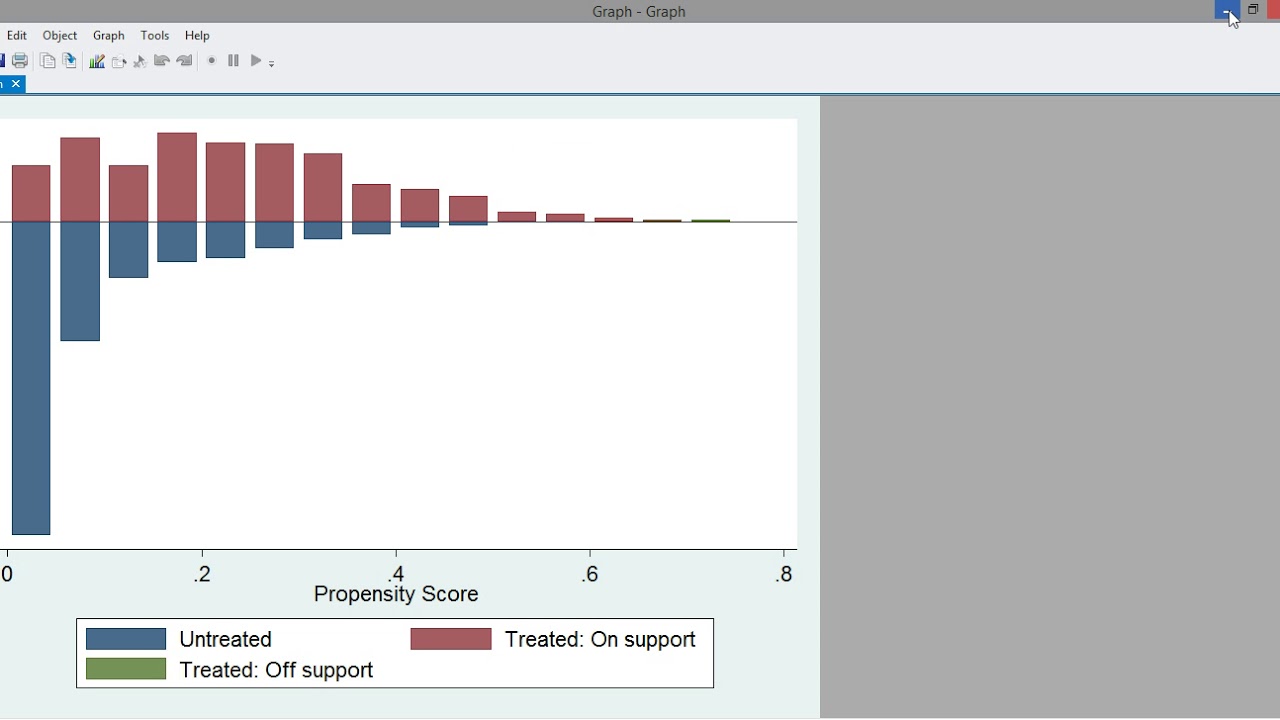
This is well known finding from previous empirical and simulation studies.
Propensity score matching table.

Full Text Review Propensity Score Methods With Application To The Help Clinic C Oams

Table 5 From Multicentre Propensity Score Matched Analysis Of Laparoscopic Versus Open Surgery For T4 Rectal Cancer Semantic Scholar

Pdf A Tutorial And Case Study In Propensity Score Analysis An Application To Estimating The Effect Of In Hospital Smoking Cessation Counseling On Mortality

Full Text An Evaluation Of Exact Matching And Propensity Score Methods As Applie Por

Full Text Get The Most From Your Data A Propensity Score Model Comparison On Re Ijgm

Pdf Propensity Score Matching A Conceptual Review For Radiology Researchers

View Image

Standardized Differences Before And After Propensity Score Matching Download Scientific Diagram
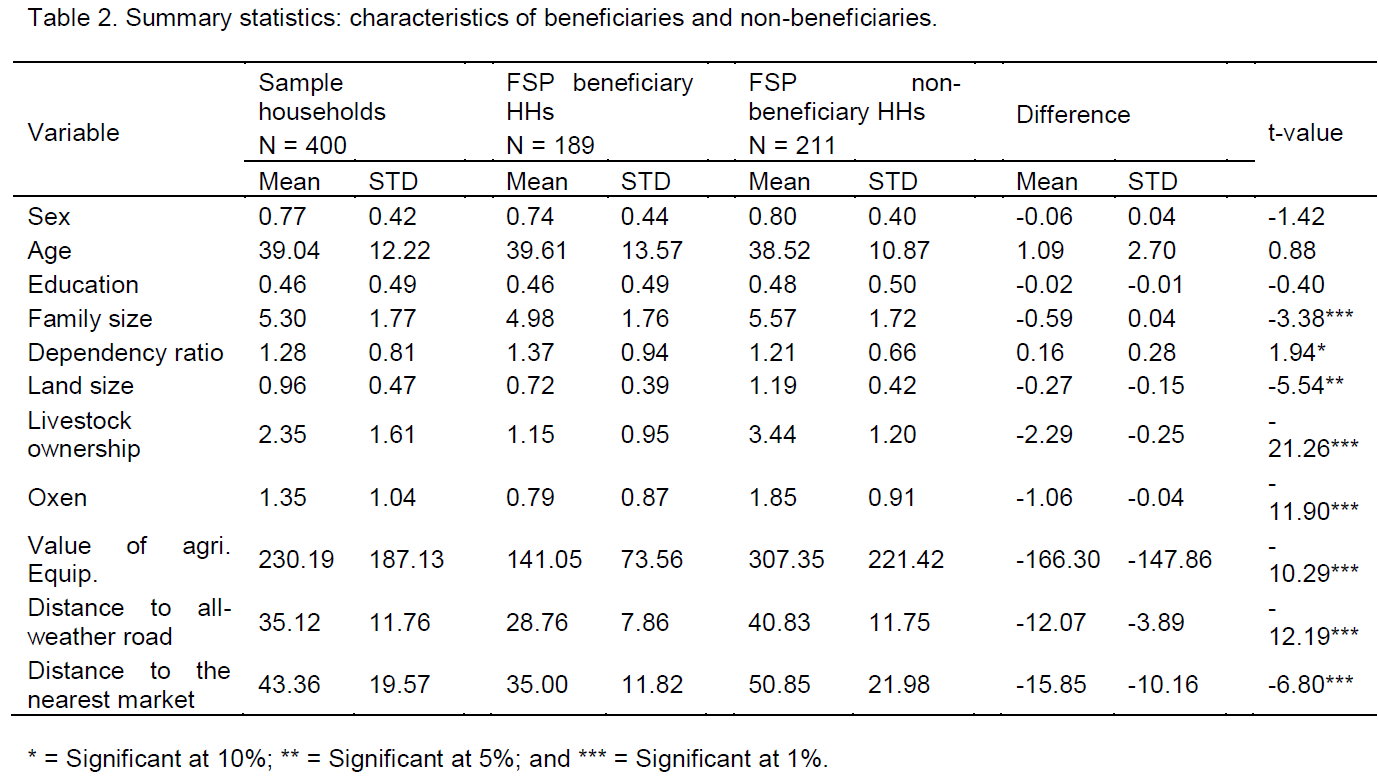
Journal Of Development And Agricultural Economics Estimating The Impact Of A Food Security Program By Propensity Score Matching

Pdf The Use Of Propensity Score Matching In The Evaluation Of Active Labour Market Policies
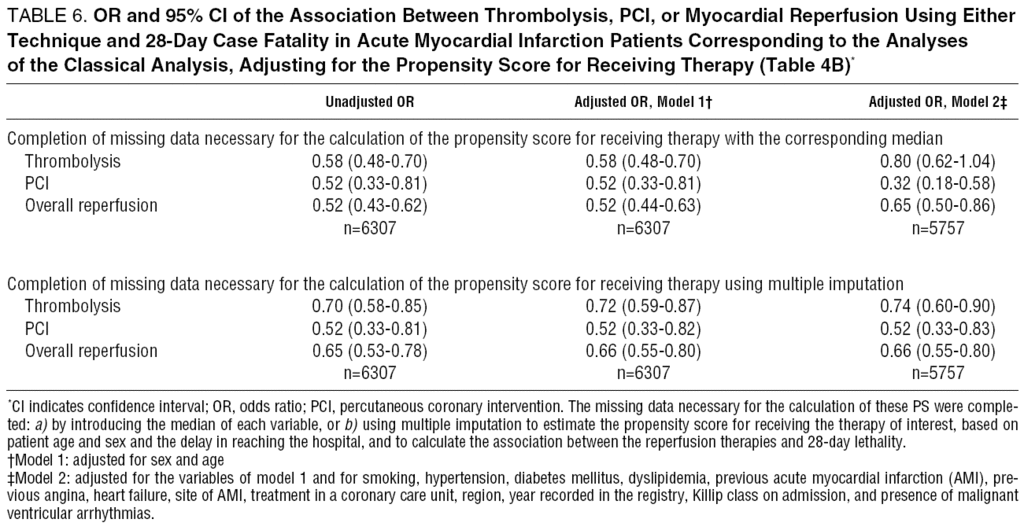
Analysis With The Propensity Score Of The Association Between Likelihood Of Treatment And Event Of Interest In Observational Studies An Example With Myocardial Reperfusion Revista Espanola De Cardiologia English Edition

Pdf Reducing Bias In A Propensity Score Matched Pair Sample Using Greedy Matching Techniques Semantic Scholar

Propensity Score Matching In Stata Youtube

Chapter 2 Overview Of Propensity Score Methods Semantic Scholar
Https Support Sas Com Resources Papers Proceedings17 Sas0332 2017 Pdf
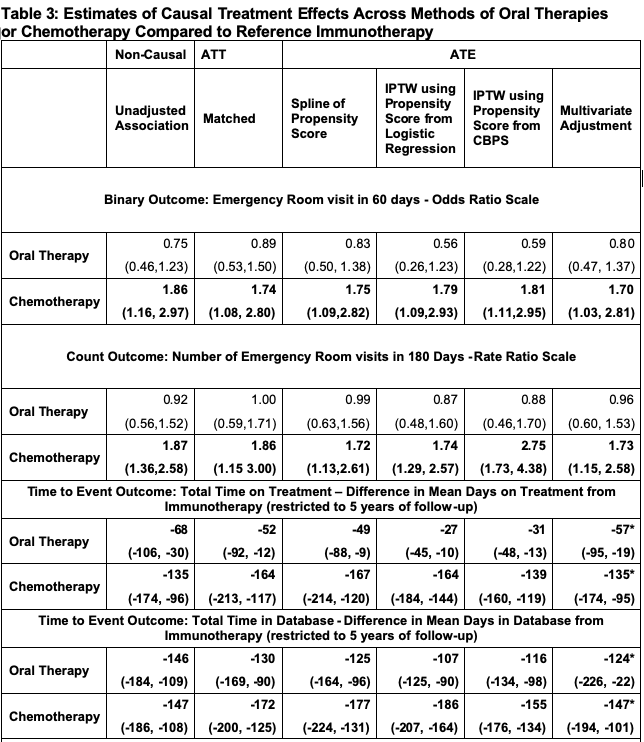
Veridical Causal Inference Propensity Score Tutorial With R Code

Pdf Propensity Score Matching With Limited Overlap

Pdf Juvenile Transfer And Recidivism A Propensity Score Matching Approach

Pdf Assessing Bias In The Estimation Of Causal Effects Rosenbaum Bounds On Matching Estimators And Instrumental Variables Estimation With Imperfect Instruments

Pdf A Propensity Score Approach In The Impact Evaluation On Scientific Production In Brazilian Biodiversity Research The Biota Program

Early Outcomes Of Robot Assisted Versus Thoracoscopic Assisted Ivor Lewis Esophagectomy For Esophageal Cancer A Propensity Score Matched Study Semantic Scholar

Propensity Score Matching In R

Comparison Of Covariate Balance Between Nsaids And Acetaminophen Before Download Table

Pdf Weight Trimming And Propensity Score Weighting
Source : pinterest.com
